
 건전한 경마를 추구하는 대한민국 대표 경마 커뮤니티
건전한 경마를 추구하는 대한민국 대표 경마 커뮤니티



- 이주의경마 시간표
- 지난경마 AI복기
- AI 종합리포트
- AI Year Chart
- 경마 전문가리포트
- 말 승률/상금 Top 50
- 기수 승률 Top 20
- 조교사 승률 Top 20
- 마주 승률/상금 Top 20
- 대박 배당률 Top 100
- 대상경주 배당률 Top 50
- 마사회 평균 배당률
- 지역별 최고 배당률
- AI 경마시스템
X
X









 분석 결과
분석 결과이번 장에서는 서울시 경마 경기의 우승마를 예측하기 위하여 1) 순위를 기반으로 한 모형, 2) 기록을기반으로 한 모형을 적합하여 경기별 우승마 예측률을 비교해보고, 예측 모형에 포함된 중요한 변수에 대하여 알아본다.
2014년 1월부터 2015년 4월까지의 자료인 총 1474회의 경기 중 임의로 70%의 경기를 train data로 30%의 경기를 test data로 나누어 test data에서의 예측률을 모형 비교의 지표로 사용하였다. 위와 같은 과정을 100회 반복 시행하여 평균 예측률을 비교하고 최적 모형을 구하고자 한다.
그리고 2015년 5월 한 달간 자료인 109회의 경기에 최적 모형을 적용하여 도출한 예측률과 실제 배당률을 적용한 배당 금액을 계산하여 비교한다. 우리는 분석에서 중요변수 도출과 최종모형 선택은 다음과 같이 수행하였다.
우선 선형모형의 경우에는 일단 마지막 1달치 데이터를 제외한 모든 데이터를 사용해서 선형모형을 적합하고 AIC/BIC 값을 최소화 하는 최적의 모형을 구하고 이 때 선택된 설명변수들을 저장한다.
Table 2.4. Description of variables
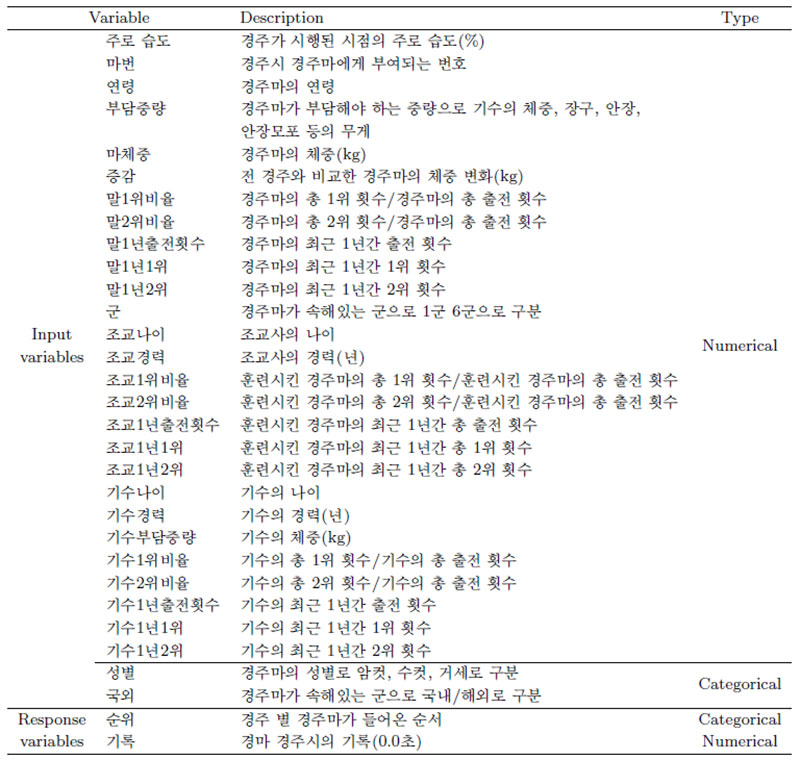
그리고 train/test로 나누어서 train data에서 이 설명변수들을 사용해서 모형을 적합한다. 물론 train data는 매번 random하게 선택되므로 회귀계수 값들은 달라지지만 사용된 설명변수는 동일하다.
마지막 1달치 데이터에 적용한 최종 선형 모형은 100개의 test data에서 test error가 가장 적은 모형을 선택한다. 랜덤 포레스트의 경우는 다른 방법을 이용하였다. 랜덤포레스트에서는 OOB error를 제공하므로 100개의 train set에서 적합된 모형 중에서 OOB error가 가장 적은 모형을 최적의 모형으로 선택한다.
그리고 이 최적 모형에서 산출된 variable importance를 기반으로 중요변수를 도출한다. 마지막 1달치 데이터에 적용된 최종모형은 100개의 test data에서 test error가 가장 적은 모형을 선택한다.


 통합검색
통합검색








