
 건전한 경마를 추구하는 대한민국 대표 경마 커뮤니티
건전한 경마를 추구하는 대한민국 대표 경마 커뮤니티



- 이주의경마 시간표
- 지난경마 AI복기
- AI 종합리포트
- AI Year Chart
- 경마 전문가리포트
- 말 승률/상금 Top 50
- 기수 승률 Top 20
- 조교사 승률 Top 20
- 마주 승률/상금 Top 20
- 대박 배당률 Top 100
- 대상경주 배당률 Top 50
- 마사회 평균 배당률
- 지역별 최고 배당률
- AI 경마시스템
X
X









 예측 모형 결과 분석 방법
예측 모형 결과 분석 방법본 장에서는 이전 장에서 제시했던 경마경주의 4가지 예측모형의 검증을 통해 최적의 예측모형을 선정하고자 한다.
2010년 1월 ~ 2013년 7월까지의 경주데이터 중 Training data에 사용 되지 않은 총 755 경주의 데이터인 Test data를 이전 장에서 제시한 단계적 회귀분석을 통해 도출된 식을 사용하여 경주마들의 기록을 예측한 뒤, 경주 별로 경주마들의 순위를 부여하여 실제 기록과 비교하는 작업을 거쳐 검증을 진행하였다. 모형의 성능을 평가하기 위하여 본 연구에서는 (6)과 같은 변수를 설정하였다.

위와 같은 변수를 토대로 (7)와 같이 성능지표(Performance measure)를 설정하였다.
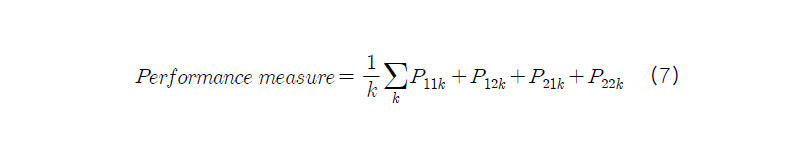
위 성능지표는 1,2등 할 것이라고 예측한 말이 실제로 1,2등 하는 평균 말의 수를 의미하게 된다. 즉, 한 경주에서 1등할 것이라고 예측한 말이 2등을 하고 2등할 것이라고 예측한 말이 1등을 한 경우
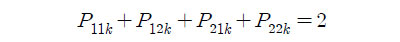
가 되고, 한 경주에서 1등할 것이라고 예측한 이 1등을 하고 2등할 것이라고 예측한 말이 1,2등을 하지 못했다면
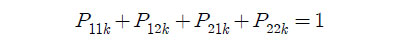
이 된다. (7)의 성능지표는 이와 같은 값들의 합을 경주 수로 나눈 값이기 때문에 1,2등할 것이라고 예측한 말이 실제로 1,2등하는 평균 말의 수를 의미한다.


 통합검색
통합검색








