
 건전한 경마를 추구하는 대한민국 대표 경마 커뮤니티
건전한 경마를 추구하는 대한민국 대표 경마 커뮤니티



- 이주의경마 시간표
- 지난경마 AI복기
- AI 종합리포트
- AI Year Chart
- 경마 전문가리포트
- 말 승률/상금 Top 50
- 기수 승률 Top 20
- 조교사 승률 Top 20
- 마주 승률/상금 Top 20
- 대박 배당률 Top 100
- 대상경주 배당률 Top 50
- 마사회 평균 배당률
- 지역별 최고 배당률
- AI 경마시스템
X
X









 다중선형회귀 분석을 이용한 예측 모형
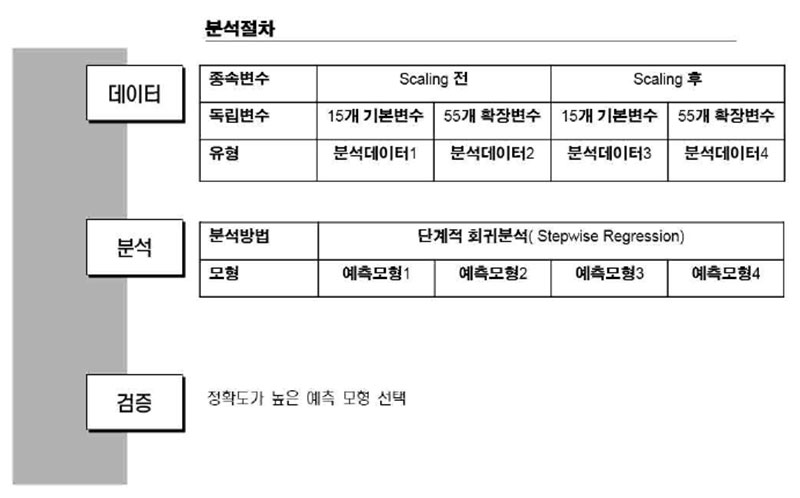
다중선형회귀 분석을 이용한 예측 모형본 연구의 경마순위에 대한 데이터마이닝을 위해 아래와 같은 연구의 절차를 구성하였으며, 2010년 1월 ~ 2013년 7월까지의 경주데이터 중 랜덤하게 추출하여 총 3,017 경주의 Training data 데이터를 사용하였다. 분석단계에서는 데이터마이닝에 중점을 두어 여러 가지 모형을 만들어 그 중 최적의 모형을 찾아내는데 있다.
데이터 병합 및 Scaling을 사용하여 변수를 다르게 하여 총 4가지 모형을 만들어 최적의 모형을 찾고 모형의 실제 예측력을 검증해보고자 한다. 먼저 종속변수 기록의 데이터 같은 경우 데이터 형태가 경마경주의 거리별로 차이를 보이고 있으며 동일한 경주에서 데이터 자체에 차이가 작게 나타난다.
즉, 동일한 경주에서 가장 먼저 골인지점에 들어온 경주마와 마지막으로 골인지점에 들어온 경주마의 기록 차이는 10초 이내로 몇 초정도에 불과하며 경주별 비교를 했을 때의 차이는 경주거리 때문에 많은 시간적 차이를 보이고 있다.
이런 경우 종속변수의 민감도의 문제와 표준화적이지 않은 문제로 분석 결과에 영향을 줄 수 있다고 판단되어 종속변수의 0 to 1 Scaling을 통하여 새로운 정규화한 기록으로 종속변수를 추가 설정하였다. 0 to 1 scaling 의 방법은 경주별 기록을 0부터 1사이 값으로 정규화 하여 정규성과 민감도의 문제를 해결하였으며 그 산출식은 다음과 같이 정의 한다.
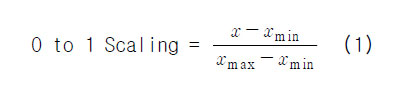
연구 분석에는 종속변수의 Scaling 전의 데이터와 후의 데이터를 모두 사용하여 각각 예측모형을 만들고자 한다.
독립변수의 경우는 경주경마의 정보인 21가지 변수와 추가로 수집한 12가지 경주마의 정보, 20가지 기수의 정보, 20 가지 경주마감독의 정보가 있다. 예측모형은 기본 모형으로 실제 경주경마의 정보인 21가지 변수만을 사용하여 분석한 기본모형과 추가로 수집한 정보를 병합하여 구성한 61가지 변수로 분석한 확장모형을 제시하고자 한다.
예측모형은 다중선형회귀분석을 사용하며 단계별 변수 선택법을 사용하여 분석을 진행하였다. 일반적으로 회귀분석은 독립변수와 종속변수간의 관계를 검증하여 독립변수가 종속변수에 미치는 영향력을 알아보거나, 독립변수의 변화에 따라 종속변수의 변화를 예측하기 위해서 사용되는 통계적 분석 방법이다.
독립변수의 개수에 따라 독립변수가 한 개인 경우는 단순회귀분석(Simple Regression Analysis),둘 이상인 경우는 다중회귀분석(Multiple Regression Analysis)이라고 한다.
회귀분석은 하나의 종속변수를 설명할 수 있는 많은 독립변수가 있는 경우 회귀모형에 사용할 변수를 축차적으로 하나씩 선택하거나 제거하여 가장 좋은 회귀모형을 선택하는 방법으로 진행하는 경우가 일반적이다.
변수선택 방법으로는 전진선택법(forward seletion method), 후진제거법(backward elimination method), 단계별선택법(stepwise selection method)등이 있으나 전진선택법은 한 변수가 선택되면 이미 선택된 변수 중 중요하지 않은 변수가 있을 수 있다.
이러한 단점을 보완하기 위해 전진선택법의 각 단계에서 이미 선택된 변수들의 중요도를 다시 검사하여 중요하지 않은 변수를제거하는 방법인 단계별선택법을 사용하였고, 보통 단계별선택법에서 선택 된 변수들을 사용한 회귀모형을 이용하는 법을 단계적 회귀분석이라 한다.
본 분석에서 모형에 새 항을 입력하기 위한 기준인 Entry criteria(입력할 변수에 대한 알파)와 새항을 제가하기 위한 기준인 Leave criteria(제거할 변수에 대한 알파)는 모두 0.05로 설정하여 변수를 선택하는 기준으로 사용하였다.
아래 그림 3.3 경마순위 데이터 분석절차는 본 분석방법에 대한 이해를 높이기 위해 정리한 그림이다.


 통합검색
통합검색








