
 건전한 경마를 추구하는 대한민국 대표 경마 커뮤니티
건전한 경마를 추구하는 대한민국 대표 경마 커뮤니티



- 이주의경마 시간표
- 지난경마 AI복기
- AI 종합리포트
- AI Year Chart
- 경마 전문가리포트
- 말 승률/상금 Top 50
- 기수 승률 Top 20
- 조교사 승률 Top 20
- 마주 승률/상금 Top 20
- 대박 배당률 Top 100
- 대상경주 배당률 Top 50
- 마사회 평균 배당률
- 지역별 최고 배당률
- AI 경마시스템
X
X









 경마 순위 데이터 분석
경마 순위 데이터 분석♣ 자료수집 방법 및 자료의 구성
경마에서 경주결과를 바탕으로 발생하는 다양한 데이터를 가지고 경주를 예측할 수 있는지 조명해보고 어떠한 자료가 경마경주에 유의미한 자료인지 검증하기 위해 본 연구를 구성하였다. 경마경주에서 발생하는 모든 정보에 데이터마이닝의 기본 근거를 두고 경마경주 결과를 회귀분석을 통해 분석하고 예측모형 검증을 이용하여 최적의 예측모형을 만들어보고자 한다
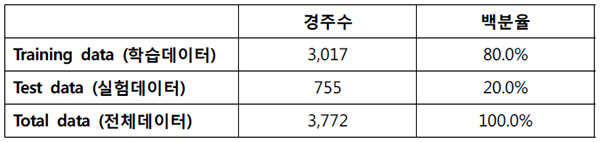
본 연구에 이용된 자료는 한국마사회에서 제공하는 경주경마 자료로 2010년 1월 ~ 2013년 7월까지 시행된 서울경마경주정보의 자료를 토대로 구성되었다. 총 3,772회의 경주에서 발생한 데이터를 이용하였고 예측모형개발을 위한 Training data(학습데이터)와 모형검증을 위한 Test data(실험데이터)를 나누어 분석을 진행하였다.
Training data 은 2010년 1월 ~ 2013년 7월까지의 경주데이터 중 랜덤하게 추출하여 총 3,017 경주의 데이터를 사용하였고 Test data 은 2010년 1월 ~ 2013년 7월까지의 경주데이터 중 Training data에 사용되지 않은 총 755 경주의 데이터를 사용하였다.
예측모형 분석을 위해 SAS 통계프로그램을 사용하였으며, 상관분석과 산점도를 위해 Minitab 16 통계프로그램을 사용하였다.
Minitab 통계프로그램은 그래프 분석하기에 SAS보다 좀 더 편리하고 시각적으로 좋기 때문에 시각화된 분석에서는 Minitab 16을 활용하였다. 모형 검증을 위해 Python 으로 모형을 프로그래밍 하여 검증을 진행하였다. 분석을 위한 데이터 구성요약은 표3.1과 같다.
표 3.1 분석 데이터 자료 구성


 통합검색
통합검색








